🤗 Hugging Face представил технику асинхронного батчинга для LLM, которая устраняет ключевой недостаток стандартного continuous batching — синхронное ожидание CPU и GPU. В обычном режиме процессор и в
Решение — разделить подготовку батча на CPU и вычисления на GPU, запустив их параллельно. Для этого используются CUDA streams (потоки) и CUDA events (события синхронизации). Потоки позволяют выполнять операции конкурентно, а события — корректно синхронизировать данные без блокировки GPU.
Ещё в ленте

Business
💵 Figma отчиталась за Q1: выручка растёт, но рынок сомневается
15.05.26
Tech
❗️CHAL: новая архитектура для дебатов ИИ на основе иерархических агентов
15.05.26
AI
🔨 Настоящие проигравшие в суде Маска против Альтмана
15.05.26
Business
🕶 Graphon AI выходит из тени с $8,3 млн на создание недостающего слоя данных для LLM
15.05.26
Tech
🤖 Физический AI выходит на заводы: компании тестируют человекоподобных роботов
15.05.26
Tech
Perplexity запускает коннектор к Snowflake для запросов на естественном языке
15.05.26
Tech
🤖 Когда ИИ начнёт строить себя сам: стартап Ричарда Сокера на $650 млн
15.05.26
AI
👩⚕️ Аудитория Онтарио выявила, что ИИ-секретари врачей выдумывают данные
15.05.26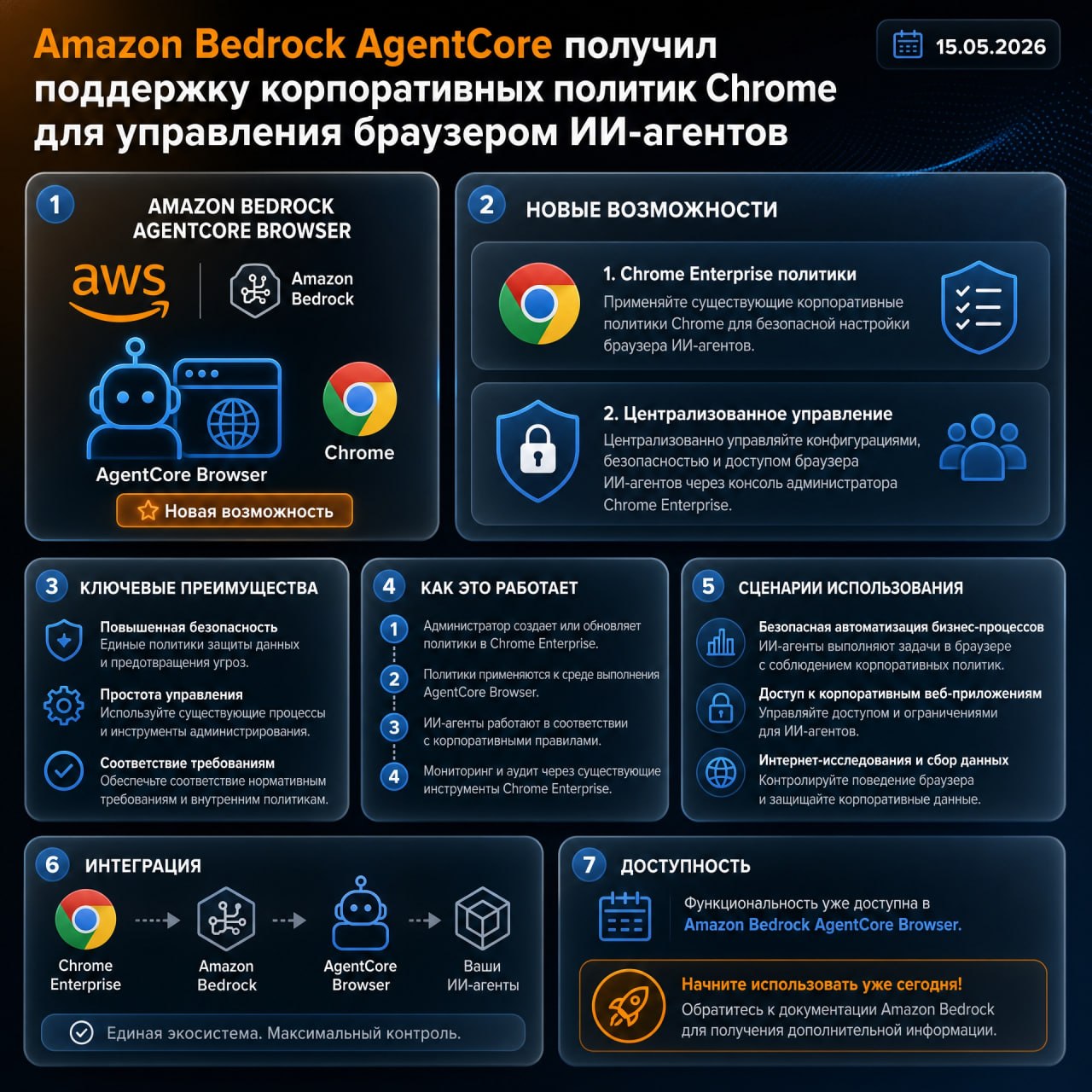
AI
☁️ Amazon Bedrock AgentCore получил поддержку корпоративных политик Chrome для управления браузером ИИ-агентов
15.05.26
Business
❗️ Неожиданный баг в ClickHouse замедлил биллинг Cloudflare
15.05.26
AI
❓ Готовность данных для агентного ИИ в финансовом секторе
15.05.26
Business